
출처: https://databasetown.com/basics-of-reinforcement-learning/
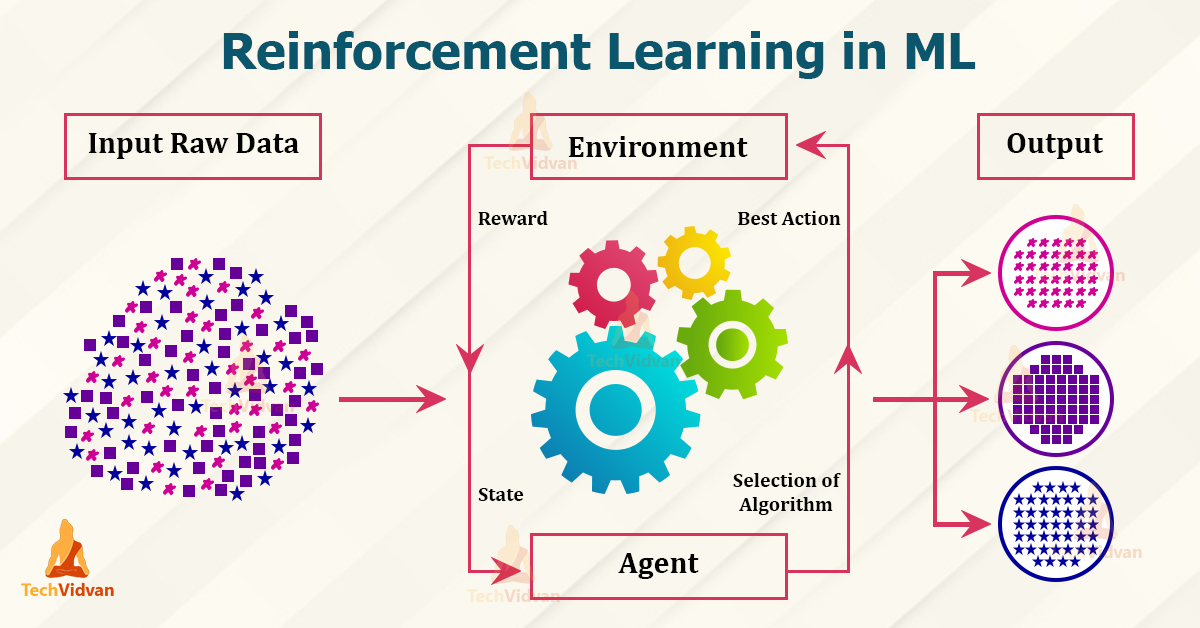
강화학습은 에이전트(Agent)가 환경(Environment)과 상호작용하며, 보상(Reward)을 최대화하는 방향으로 학습하는 기계학습의 한 분야이다.
강화학습은 지도학습처럼 정답을 미리 알지 않고, 에이전트가 시도한 행동의 결과에 따라 주어지는 보상 값을 기반으로 학습한다. 이는 시행착오를 통해 더 나은 전략(정책)을 스스로 발견하는 방식이다.
[예시] 엣지 오브 투모로우 (Edge of Tomorrow)
• 개요
가까운 미래, '미믹'이라 불리는 외계 종족의 침략으로 인류는 멸망 위기를 맞이하게 된다. 인류는 그에 대항해 전 세계 군대가 모두 연합한 연합군인 연합방위군(United Defence Force, UDF)을 창설하고, 방위군의 정훈장교였던 미 육군 소령 빌 케이지(톰 크루즈 분)는 자살 작전이나 다름없는 작전에 훈련이나 장비를 제대로 갖추지 못한 상태로 배정되고 전투에 참가하자마자 죽음을 맞는다.
하지만 불가능한 일이 일어난다. 그 끔찍한 날이 시작된 시간에 다시 깨어나 전투에 참여하게 되고 죽었다가 또 다시 살아나는 것. 외계인과의 접촉으로 같은 시간대를 반복해서 겪게 되는 타임 루프에 갇히게 된 것이다.
• 영화 제목을 "엣지 오브 투모로우"라고 한 이유는?
"Edge of Tomorrow"는 '내일의 경계', 즉 내일로 가는 오늘의 마지막 끝인 11시 59분을 의미한다. 주인공 빌 케이지의 시간은 '오늘'이 계속 반복되고 있다.
철학적 관점에서 내일(새로움이 생겨나는 날, 혹은 넘어가기 어려운 단계)로 가는 경계를 의미한다. 주인공이 죽기 직전의 순간, 내일로 넘어가지 못하는 경계에서 갇혀 버린 상황을 표현한다.
원래 이 영화는 일본 소설 "All You Need Is Kill"이 원작인데, 2013년 여름에 제목이 'Edge of Tomorrow'로 변경되었다. 영어 원어민에게 원제가 다소 어색하게 느껴졌기 때문으로 보인다.
더그 라이만 감독은 영화의 내용(살고, 죽고, 반복한다)을 잘 반영하는 'Live, Die, Repeat'를 선호했지만, 워너 브라더스는 제목에 'Kill'이 들어가는 것에 대한 부정적인 반응을 우려하여 'Edge of Tomorrow'로 결정했다.
[예시] 슈퍼 마리오

오락실에서 유행한 게임 중 "슈퍼 마리오"가 있다. "슈퍼 마리오"는 마리오를 움직여 여러 장애물을 피하고 적을 물리쳐 제한 시간 안에 목표 지점까지 가야 승리하는 게임이다.
처음에 아무런 정보 없이 "슈퍼 마리오"를 시작하면 금방 게임이 끝나 버린다. 어떻게 적을 물리쳐야 하는지, 장애물은 어떻게 피해야 하는지 알지 못하기 때문이다. 그러나 게임을 한두 번 해 보면 방법을 차차 알게 된다.
이처럼 게임 방법을 배우는 과정은 "슈퍼 마리오"에만 해당하는 것이 아니다. 게임 외의 영역에서도 일상생활 속에 존재하는 인간의 자연스러운 학습 과정이다.
인간의 사고 방식을 모방한 인공지능에서도 이러한 시행착오를 통한 학습이 이루어진다. 시행착오를 겪으며 계속 학습하는 방식, 이것이 바로 강화 학습이다.
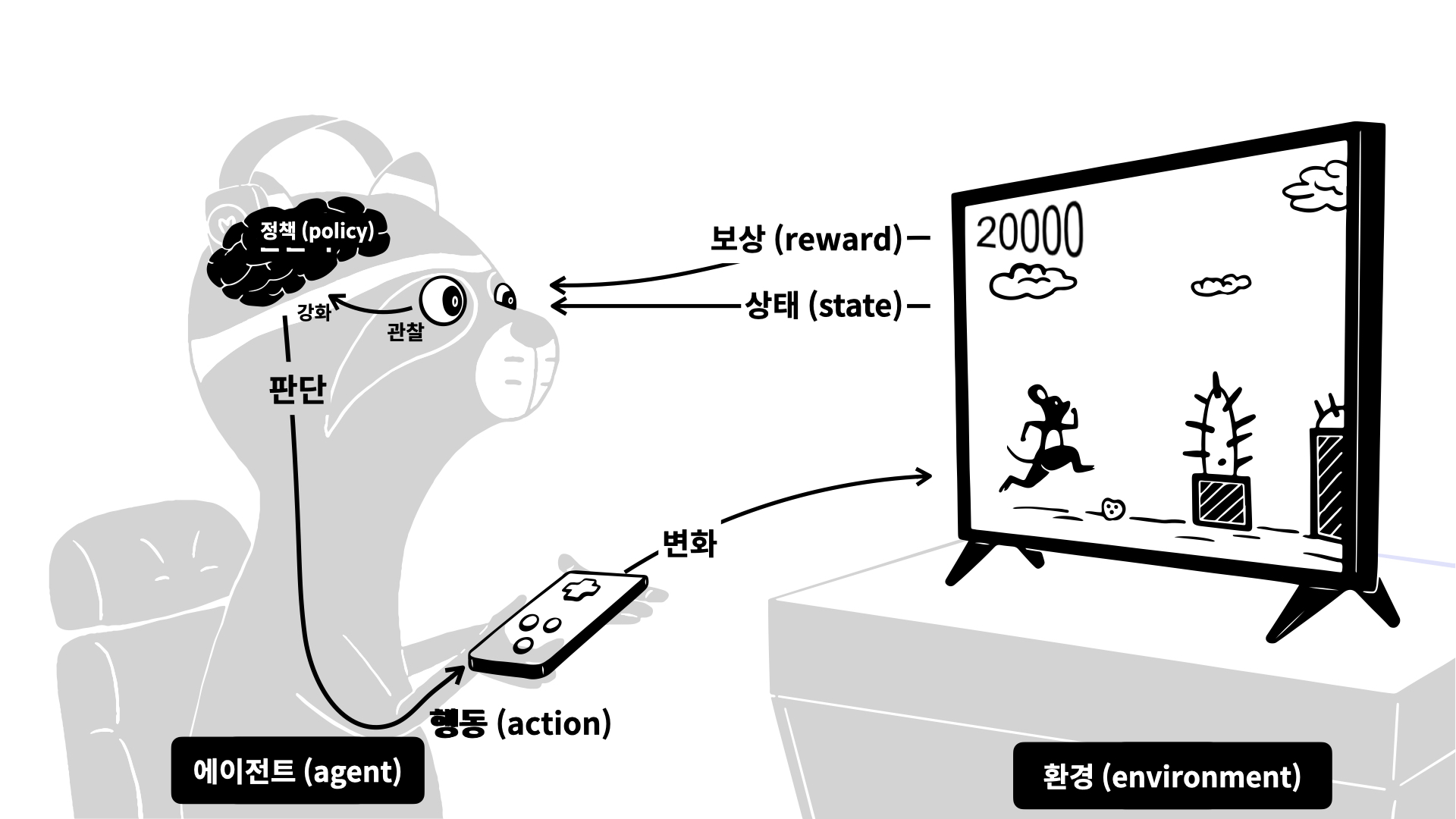
강화학습은 다음의 반복 루프를 통해 학습이 이루어진다.
강화학습에는 다양한 알고리즘이 존재하며, 대표적인 것은 다음과 같다.


보상모델은 명시적인 보상이 존재하지 않는 복잡한 환경에서, 인간 또는 AI 피드백을 바탕으로 행동의 품질을 평가하여 강화학습에 활용된다.
예: 언어모델에서는 다음과 같은 절차로 보상모델을 사용한다.
AlphaGo는 인간 기보로 초기 학습한 뒤, 자기대국(self-play)을 반복하며 강화학습으로 전략을 개선했다. 알파고 제로는 인간 데이터 없이 바둑 규칙만으로 강화학습을 수행해 기존 AlphaGo를 압도했다.
“강화학습은 AI가 자율적으로 판단하고, 경험을 통해 개선할 수 있는 길을 열었다.” – 데미스 하사비스


